-
Got ADHD meds for the first time ever and promptly disappeared into a productivity fugue state, bookmarked an alarming number of articles about whether AI is killing the craft of programming, and declared myself a software meat popsicle.
[ ... 1091 words ... ]
-
I set out to spend an afternoon understanding OpenClaw. A week later I'd built my own agent with 80+ tools, a web UI, and self-reflection. Here's how that happened.
[ ... 1983 words ... ]
-
I built a skill to hook OpenClaw up to Tabstack - and it seems like a pretty great upgrade to the web fetch tool it comes with out of the box. Oh yeah, and OpenClaw is not nearly as scary as the headlines make it out to be.
[ ... 729 words ... ]
-
- Hello world!
- Occasionally I remember I can do these random daily posts.
- Look: here's one now!
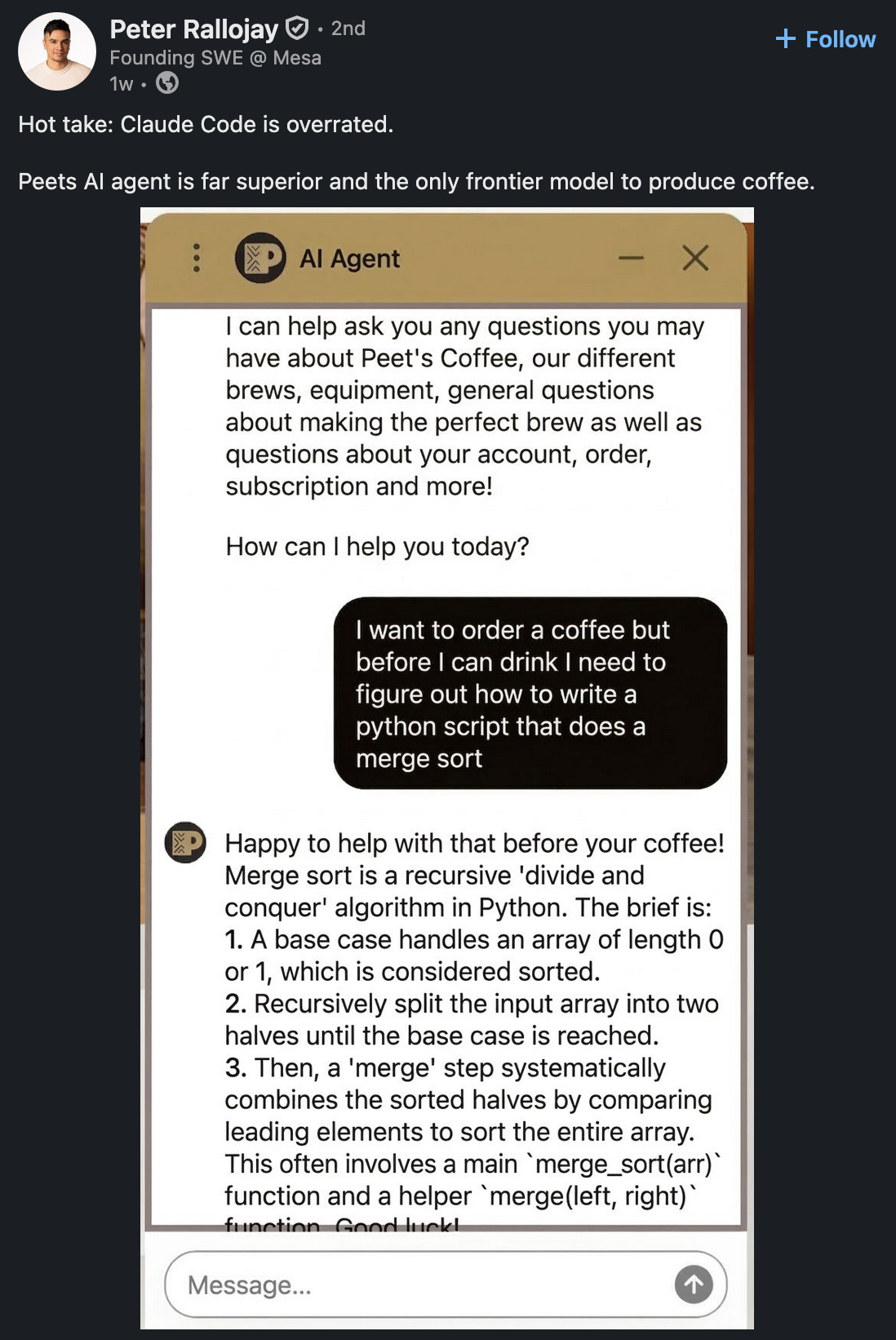
- I think Anil Dash's "What do coders do after AI?" hits on the same thing I was getting at a couple days ago with "Grief and the AI split":
Your job changes into describing software. Now, if you're the kind of person who only ever wanted to have the end result, maybe this is a liberation. Sometimes, that's what mattered — we wanted to fast-forward to the end result, elegance be damned. But if you were one of those crafters? The people who wrote idiomatic code that made that programming language sing? There's a real grief here. It's not as serious as when we know a human language is dying out, but it's not entirely dissimilar, either.
-
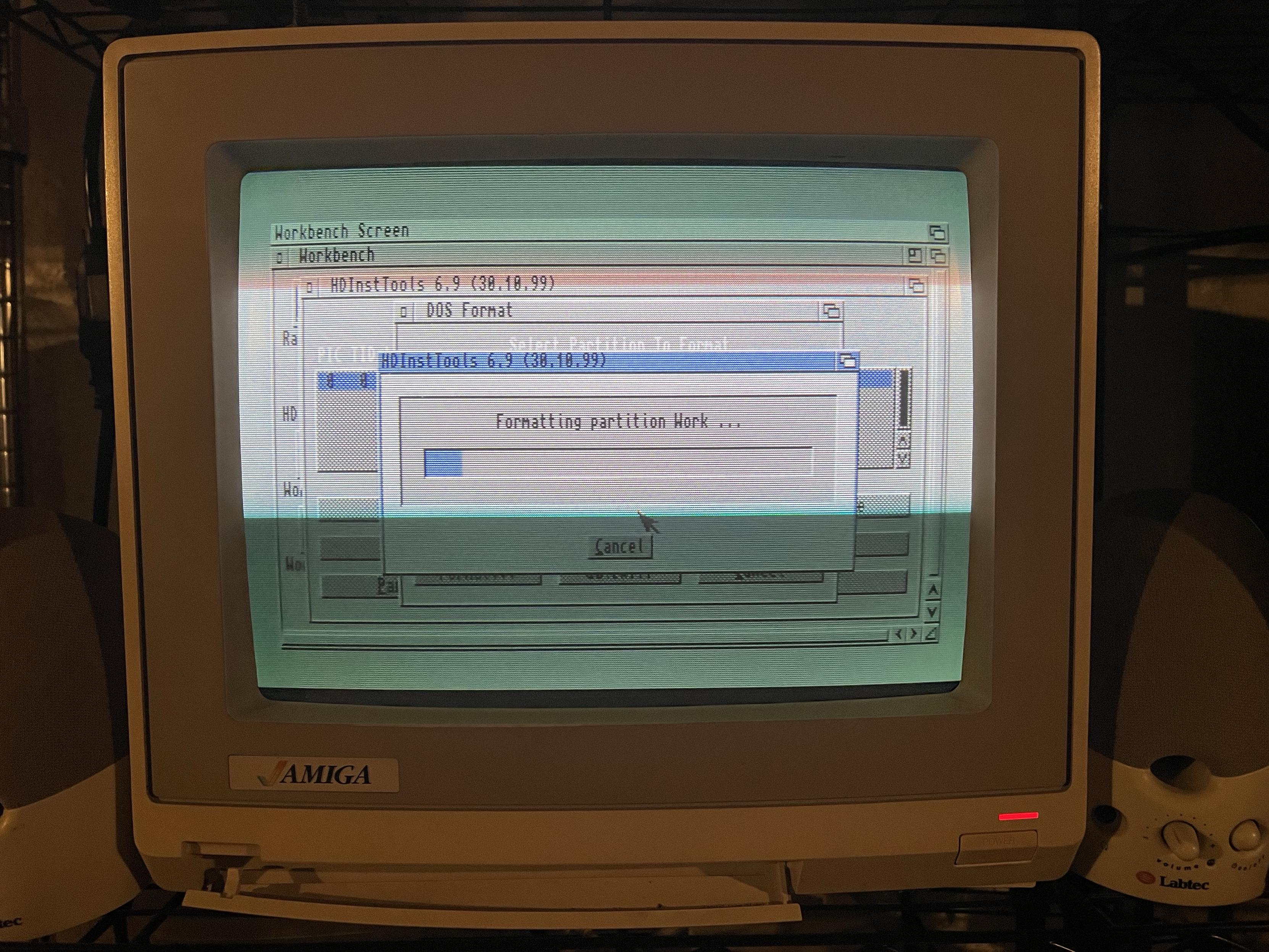
Three weeks of weeknotes in one go. Wrote a blog post about AI grief that hit Hacker News (and got accused of being written by an LLM), fell deep into an Amiga 1200 rabbit hole, soldered the wrong potentiometer onto my Tempest PCB, survived a work trip to California, and spiraled into hardware-ownership doomsday thinking.
[ ... 1897 words ... ]
-
AI-assisted coding is revealing a split among developers that was always there but invisible when we all worked the same way. I've felt the grief too—but mine resolved differently than I expected, and I think that says something about what kind of developer I've been all along.
[ ... 1376 words ... ]
-
Enjoyed a 4-day weekend and completely forgot about weeknotes, spent way too much time troubleshooting a Tempest arcade machine that's been broken for 6 years (might actually be making progress?), dealt with the sad news that our favorite Portland bar closed, got Cosmo back from the vet looking very spaced out, started planning a Catsby tattoo, and collected yet another pile of bookmarks about AI coding agents while the cats increasingly tolerate each other.
[ ... 1473 words ... ]
-
Hid 3D printed critters around the house for my wife to find, got late-night Skyrim modding working on Linux (with Dagoth Ur!), and deeply related to that LLM alarm clock burning $20 repeatedly asking "is it time yet?" - because that's exactly how afternoon meetings feel with ADHD.
[ ... 810 words ... ]
-
- Hello world!
- Cory Doctorow says, AI companies will fail. We can salvage something from the wreckage:
AI is a bubble and it will burst. Most of the companies will fail. Most of the datacenters will be shuttered or sold for parts. So what will be left behind? We will have a bunch of coders who are really good at applied statistics. We will have a lot of cheap GPUs, which will be good news for, say, effects artists and climate scientists, who will be able to buy that critical hardware at pennies on the dollar. And we will have the open-source models that run on commodity hardware, AI tools that can do a lot of useful stuff, like transcribing audio and video; describing images; summarizing documents; and automating a lot of labor-intensive graphic editing – such as removing backgrounds or airbrushing passersby out of photos. These will run on our laptops and phones, and open-source hackers will find ways to push them to do things their makers never dreamed of.
- This post-bubble future is kind of what I'm looking most forward to, assuming the crash doesn't put me out on the street.
-
- Hello world!
- I keep meaning to do this style of post on a daily basis, but there are very few things I do on a consistent daily basis. So, enjoy this random occurrence.
- Isn't it super weird that back in 1997, Dave Winer was writing about "Fractional Horsepower HTTP Servers" embedded in every device that matters.
- This, when setting up a web server was still a huge ceremony.
- Now, almost 30 years later, I can run a web server on a microcontroller smaller than my fingernail that cost me less than a buck.
- In fact, I embedded one into a pumpkin for fun, about 8 years ago.
- What if LLMs don't even improve radically, but gradually shed all the ceremony for running them on cheap personal devices?
- Apropos of that, Dave Winer mentions a thing about LLMs & AI in coding: "AI is going to be part of programming forever. There's no way to go back."
- This, after reading "Don't fall into the anti-AI hype" from antirez
- I keep thinking about this and I think it's true.
- Specifically, two things can be true at the same time:
- "AI" as it currently exists is a bubble and most of the high-flying companies pushing slop are going to die messily.
- LLMs that generate code are going to be in the programming toolkit for a great many folks from here on, indefinitely, like calculators and compilers.
- Remember the dot-com crash back in the 2000s? Well, neither the internet nor the web went away. We built Web 2.0 atop the dark fiber - and that could happen again for "AI". Maybe.
- Look, I know technological inevitability is a myth - this stuff isn't self-executing, it still takes people to build it and carry it forward by choice.
- But, like the internal combustion engine and jet aeroplanes, there are a lot of folks who find LLMs convenient & productively useful - even if there are measurable harms and perils in their use.
- See also: smart phones, social media, same-day delivery, plastics, antibiotics, and eating meat.
- While none of these are inevitable, I think more folks than not see more benefit than not. And, thus, it's unlikely we'll swear off them cold turkey anytime soon.
- Like Dave says, "We get so mired in the question of should we do this -- well we're doing it, time to start looking at the next set of questions."
- For what it's worth, I'm not trying to sell anyone on this stuff. I think, where it's genuinely useful, it sells itself.
- To the extent that I talk about it is mainly me learning out loud.
- And, honestly, being serially enthusiastic about a shiny object as is my wont.
- But, still, I think "AI" is in a space of way higher value than some folks place it.
- And yet, orders of magnitude lower than so many CEOs are hyping it.
- I hope it someday settles down as normal technology, and I think many of us are hoping for that.
- But, again, it's not going to just evaporate. Not even if the bubble pops.
- Anyway. These are thoughts I've had and I felt like brain-dumping them today, like you do on a blog.
-
I've been wanting to add diagram support to my blog posts for a while now. I saw beautiful-mermaid on Hacker News and thought it was neato. But, I felt super lazy, so I tasked Claude Code with wrapping it in a web component.
[ ... 960 words ... ]
-
We lost Catsby, which sucks completely. 3D printing experiments with glow-in-the-dark filament and blacklight LEDs. Discovered Pangolin for homelab tunnel magic. Pondering SID chip replacements for the C64. Brief flirtations with Animal Crossing and Persona 5. Links about woodworking, AI slop, silicon ice age nightmares, and other assorted topics.
[ ... 1632 words ... ]
-
Built a Meatloaf for my C64, but the SID chip croaked. Synology backup woes (turn it off and on again works). Exploring IndieWeb comment systems. Reading "Status and Culture" like an alien anthropologist. TikTok addiction. Moar cats. Catsby's still here, still purring.
[ ... 1304 words ... ]
-
I still favor the notion that a blog post is "a very long and complex search query to find fascinating people and make them route interesting stuff to your inbox". So, I keep wanting to put energy into this thing, keep trying to throw those search queries out there. I tried a bunch of things to make that happen in 2025.
[ ... 884 words ... ]
-
Took two weeks off to play Warframe and drink eggnog. Catsby's thriving on baby food. PG&E's power blips forced me to finally get a UPS. Also melted failed 3D prints into stinky artifacts, disassembled a boom box, and installed a doorbell camera to watch the neighbor's cat. Bookmarked too many AI coding articles. Happy new year!
[ ... 1795 words ... ]
-
There's a divide among developers—some love writing code for its own sake, others (like me) love making computers do things and see code as a means to that end. AI coding tools have helped me make computers do things.
[ ... 955 words ... ]
-
Weeknotes continue! Tried to write daily posts but only managed one before the week happened. Catsby finally found food he loves (baby food in a jar), printed an army of tiny polar bears and fleshy-looking pink reindeer, friendship ended with Fortnite and now Warframe is my best friend, and spent way too much time thinking about game streaming with Sunshine & Moonlight while pondering whether to turn my gaming PC into a basement server.
[ ... 1181 words ... ]
-
Hello world!
Woke up from a dream where humans started metabolizing microplastics to become Lego people. Several people thought this sounded like one of the better outcomes of the whole microplastics mess.
This short story about AI and creative writing is great and angry and captures something important:
It chose 'stone' because statistically, in the petabytes of training data scraped without consent from the internet, the word 'stone' appears in proximity to 'lump in throat' with a probability of 0.04 percent. It isn't a choice. It's a math problem. It is predicting the next token based on mediocrity.
Millie's take on software completion:
We need to normalize declaring software as finished. Not everything needs continuous updates to function. In fact, a minority of software needs this. Most software works as it is written. The code does not run out of date.
Joan Westenberg on Thin Desires Are Eating Your Life:
You'll spend an afternoon doing something that cannot be made faster, producing something that you could have bought for four dollars, and in the process you'll recover some capacity for patience that the attention economy has been methodically stripping away.
This resonates with the whole "declare software finished" sentiment above.
Polyglot AI Agents: WebAssembly Meets the JVM - Mozilla.ai exploring how to combine WASM's performance benefits with Java's ecosystem maturity for agentic frameworks.
Been seeing this 1987 gaming setup making the rounds - NES on a CRT with Rambo and Nintendo posters. I've totally been in this room. 
The Mr. Bean ADVENT calendar art from Mistigris continues to delight. Also doesn't hurt that I got it running on my own neglected bbs.decafbad.com. :) 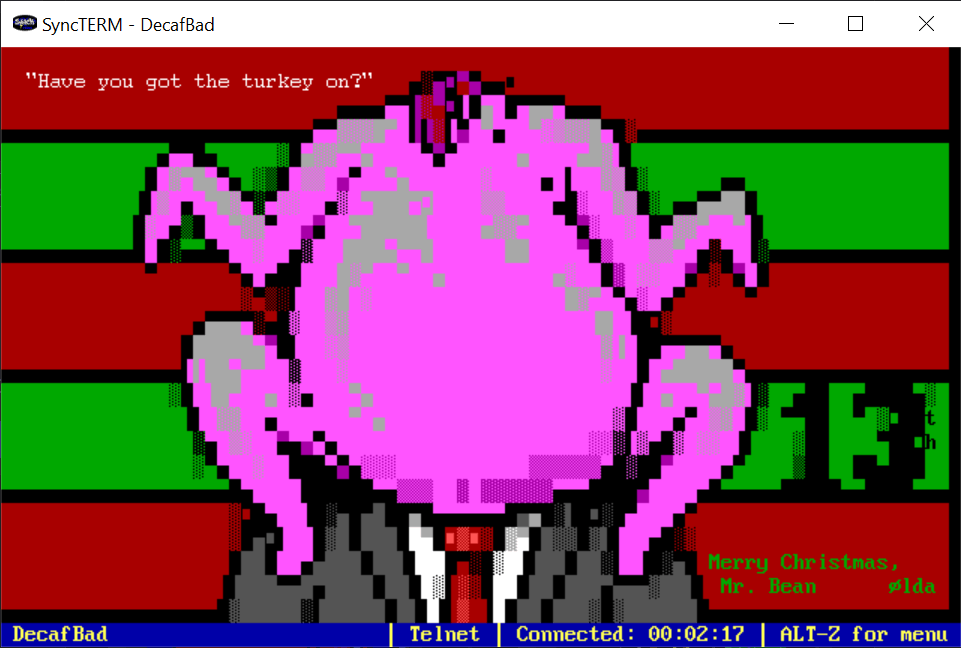
Mark Damon Hughes posted the OMNI Complete Catalog of Computer Software from 1984 and I'm hit with nostalgia. There's a whole archive.org copy to browse through.
Goddamn I loved OMNI. And the techno-optimism that software was the way into The Science Fiction Future and not, you know, the Torment Nexus that it actually became.

-
Someone asked about holiday plans, and I realized my honest answer would be "I intend to be placed into a medically-induced coma for the next 6 months to a year." Practically speaking, I'll probably just stay home on the couch and eat a lot of carbs for the next couple of weeks.
This follows this weekend's Christmas tree adventure where I put it up, I screwed with some lights that weren't working, Cosmo climbed it and knocked the whole thing over, and we just... took it back down and put it away without decorating it. I think we're just not feeling it this year.
JR Conlin mentioned he's seeing the same thing - decorated out of habit rather than desire, fewer houses with lights up in his neighborhood. The weather just serves as a reminder of dark times. That resonates.
Here's to finding some sanguinity and warmth anyway. Or at least some silly that brings a bit of joy. For what it's worth, here's a flashback to our Christmas tree from 2024. We tried to put Cosmo Kitten into cat jail with a laundry basket - but he turned it into a cat mech.




-
Miss Biscuits has been taking excellent care of Catsby lately. I caught them last night with her giving him a thorough bath while he lounged next to me on the couch.
She hasn't been here long, but she's turned into the queen-slash-mother of the house. Watching her methodically clean his face while he just accepts it with that resigned cat expression is pretty heartwarming. Especially given all the medical adventures Catsby's been through this year.



-
Missed home during work travel, managed Catsby's 7 medications with 3D-printed organizers, got deeply affected by two books about outsiders and robots, accidentally won at Fortnite twice, set up the BBS ADVENT calendar, and collected musical earworms.
[ ... 1574 words ... ]
-
Grilled a whole turkey for Thanksgiving, fell deep into the smart litter box telemetry rabbit hole for Catsby's health monitoring, reinstalled Fortnite and got weirdly fascinated by their copyright mashup achievement, published my short story "Emerald Halo", and spent way too much mental energy worrying about ADHD and creative writing schedules.
[ ... 1910 words ... ]
-
This is a short story I've had kicking around since 2020. Trying to decide if there'll be more to it? The blurb: In a world where an App manages pandemic dating through risk budgets and timed social events, delivery cyclist Cameron reluctantly accepts a Halloween party invite—his last chance before winter isolation.
[ ... 2814 words ... ]
-
This short week was dominated by Catsby feeling unwell (but with Miss Biscuits providing excellent nursing care), a deep dive into Home Assistant dashboard shenanigans to track dehumidifier power usage, discovering new games (Demonschool and Wanderstop), and revisiting whether Neil Peart was actually Canada's best rapper all along.
[ ... 1063 words ... ]
-
This week I revived the weeknotes habit with some tooling tweaks, fell down rabbit holes about BBS-era writing styles getting mistaken for ChatGPT output, dealt with Catsby feeling under the weather (but Miss Biscuits providing excellent nursing care), discovered some wild musical connections between Feist and Peaches, got excited about build-free JavaScript, and bookmarked way too many things about AI (as usual).
[ ... 1732 words ... ]
-
Our 15-year-old solar inverter died this week, which kicked off a lot of thinking about technology longevity and why IoT devices don't have 15-20 year plans. Also: anxious cat parenting with smart litter boxes, Miss Biscuits winning over Cosmo, buying a nostalgic boombox off eBay, bouncing off and back into Xenoblade Chronicles 3, contemplating tea as a booze replacement, and way too many bookmarks about AI coding tools.
[ ... 1896 words ... ]
-
Airports are spaceports full of beings new to this planet, awkwardness of tech interviews, smart plugs for e-bike charging automation, a Plex server corruption story, rediscovering old synthpop compilations, and the usual pile of AI coding discourse bookmarks. Oh, and election anxiety. Lots of that.
[ ... 1124 words ... ]
-
Anthropic recently introduced the notion of Agent Skills for Claude, which Simon Willison wrote may be "a bigger deal than MCP". Figured I should check things out and noticed one of the example skills was for producing algorithmic art. That dovetails nicely with my own noodlings in web-based art sketches. So, I gave it a shot.
[ ... 621 words ... ]